The AI world is shifting. For the last two years, the industry’s focus has been heavily tilted toward training and fine-tuning. But as AI applications move from beta tests to production environments with thousands of daily active users, a new, terrifying reality is setting in: Inference costs.
When you build a SaaS product wrapped around a managed cloud API (like OpenAI, Anthropic, or Google Gemini), your margins are entirely at the mercy of their per-token pricing. At low volumes, paying $0.60 per million output tokens feels like a steal. But what happens when your app goes viral? What happens when you process millions of customer support transcripts a day? Your API bill scales linearly with your success, punishing your profit margins.
Startups are desperate to know: At what point is it cheaper to rent a dedicated GPU server and host an open-source model yourself? We decided to find out. We ran a rigorous 100-million-token stress test comparing OpenAI's highly efficient GPT-4o-mini API against a self-hosted Meta Llama 3 (8B) model running on an iDatam dedicated GPU server powered by the blazing-fast vLLM engine.
Here is the definitive, hard-data reality of AI inference costs in 2026.
The Contenders and the Hardware Setup
To make this a fair fight, we benchmarked models in the same "weight class." We aren't testing massive frontier models here; we are testing the highly efficient, extremely fast models that power 90% of everyday AI SaaS features (summarization, sentiment analysis, basic chat, and RAG).
Contender 1: The Managed Cloud API
Model: OpenAI GPT-4o-mini
Engine: Managed API endpoint
Pricing: ~$0.15 per 1M input tokens / ~$0.60 per 1M output tokens
Contender 2: The Self-Hosted iDatam Server
Model: Meta Llama 3 (8B Instruct)
Engine: vLLM (an open-source, high-throughput memory management engine for LLMs)
The Hardware: An iDatam Dedicated GPU Server
GPU: 1x NVIDIA A100 (80GB) PCIe
CPU: AMD EPYC 7003 Series
RAM: 256GB ECC
Network: 10Gbps Unmetered Uplink
Monthly Cost: ~$1,500/month (Flat rate)
The Benchmark Methodology
Generating a few paragraphs in a web interface is not a benchmark. To find the true limits, we needed to simulate a heavy, real-world production load. We tasked both systems with generating a combined total of 100 million tokens.
We used an asynchronous Python script to hammer both endpoints with concurrent requests. The prompts consisted of a standardized 500-token input (simulating a standard RAG context retrieval) and asked for a 500-token output response.
The Data We Collected:
Tokens Per Second (TPS): The raw throughput capability of the system.
Concurrency Limits: How many simultaneous users the server could handle before Time-to-First-Byte (TTFB) latency spiked beyond acceptable UX limits (defined as >2 seconds).
The Hard Cost: The exact dollar amount spent to generate 1 million tokens under sustained load.
Open-Sourcing Our Tests: The Python Stress Scripts
Transparency is crucial in infrastructure benchmarking. If a developer looks at our data and thinks it's rigged, the results mean nothing. Below are simplified versions of the exact scripts we used to run our concurrent load tests.
1. The vLLM Local Server Setup
First, we spun up the iDatam GPU server and launched the Llama 3 model using vLLM, which utilizes PagedAttention to manage memory efficiently and maximize throughput.
# Launching the vLLM server on the iDatam dedicated GPU node
python3 -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.90 \
--max-model-len 81922. The Asynchronous Load Testing Script
We used Python's `asyncio` and `aiohttp` libraries to simulate hundreds of users hitting the endpoints simultaneously.
import asyncio
import aiohttp
import time
# Toggle between local iDatam server and Cloud API
ENDPOINT = "http://localhost:8000/v1/chat/completions" # Or Cloud API URL
API_KEY = "sk-..." # Leave empty for local vLLM if unauthenticated
HEADERS = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
# Standardized prompt: 500 tokens of input context (truncated here for brevity)
PAYLOAD = {
"model": "meta-llama/Meta-Llama-3-8B-Instruct",
"messages": [{"role": "user", "content": "Analyze the following text and summarize the key findings... [500 TOKENS OF TEXT]"}],
"max_tokens": 500
}
async def fetch(session, request_id):
start_time = time.time()
async with session.post(ENDPOINT, headers=HEADERS, json=PAYLOAD) as response:
result = await response.json()
latency = time.time() - start_time
# Extract output token count for TPS math
output_tokens = result['usage']['completion_tokens']
return latency, output_tokens
async def load_test(concurrent_requests):
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, i) for i in range(concurrent_requests)]
results = await asyncio.gather(*tasks)
return results
# Run the test with 200 concurrent users
if __name__ == "__main__":
start_time = time.time()
results = asyncio.run(load_test(200))
total_time = time.time() - start_time
total_tokens = sum([res[1] for res in results])
print(f"Total Time: {total_time:.2f}s")
print(f"Total Output Tokens: {total_tokens}")
print(f"Tokens Per Second (TPS): {total_tokens / total_time:.2f}")The Results: Performance and Bottlenecks
After pushing 100 million tokens through both systems, the data painted a fascinating picture of scaling economics.
1. Tokens Per Second (TPS) and Concurrency
Cloud API (GPT-4o-mini): Handled 200 concurrent requests easily, but we immediately ran into hard API Rate Limits (Tokens Per Minute constraints). To hit our 100M token goal, we had to artificially throttle our script to avoid HTTP 429 (Too Many Requests) errors.
iDatam Dedicated Server (vLLM): The single A100 GPU devoured the queue. At 200 concurrent requests, vLLM's continuous batching kept the GPU utilization at 98%. We achieved an astonishing 3,200 output tokens per second. Latency remained incredibly stable, with TTFB averaging around 450ms.
2. The Cost of 100 Million Tokens
To calculate the API cost, we assumed our testing ratio: 50% input tokens and 50% output tokens.
Cloud API: 50M Input ($7.50) + 50M Output ($30.00) = $37.50 per 100M tokens.
iDatam Server: The server costs $1,500/month regardless of usage. At 3,200 TPS, generating 100M tokens takes roughly 8.6 hours.
The Citeable Asset: The AI Inference Break-Even Matrix
At $37.50 per 100 million tokens, the Cloud API seems impossibly cheap. If you are a hobbyist or an early-stage startup processing a few million tokens a month, do not buy a dedicated server. Stick to the API.
But look at what happens when your application scales to enterprise production volumes. Here is the exact monthly break-even traffic point where an iDatam dedicated server destroys cloud API pricing.
| Monthly Token Volume (In/Out Combined) | Cloud API Estimated Cost (GPT-4o-mini) | iDatam Dedicated A100 Server Cost | The Winner |
|---|---|---|---|
| 100 Million Tokens | $37.50 | $1,500.00 (Flat) | Cloud API (Cheaper by $1,462) |
| 1 Billion Tokens | $375.00 | $1,500.00 (Flat) | Cloud API (Cheaper by $1,125) |
| 3 Billion Tokens | $1,125.00 | $1,500.00 (Flat) | Cloud API (Cheaper by $375) |
| 4 Billion Tokens | $1,500.00 | $1,500.00 (Flat) | THE BREAK-EVEN POINT |
| 10 Billion Tokens | $3,750.00 | $1,500.00 (Flat) | iDatam Server (Saves $2,250/mo) |
| 20 Billion Tokens | $7,500.00 | $1,500.00 (Flat) | iDatam Server (Saves $6,000/mo) |
The Data Takeaway: If your application processes more than 4 Billion tokens per month (roughly 1,500 tokens per second, 24/7), a single iDatam dedicated GPU server pays for itself. Everything beyond that 4 Billion mark is essentially free inference. At maximum sustained capacity, a single A100 running vLLM can output over 8 Billion tokens a month.
The Hidden ROI: Why Startups Move to Bare Metal Before the Break-Even Point
You might look at the matrix above and think, "We only process 2 Billion tokens a month, so we should stick with the API." However, many SaaS companies migrate to iDatam dedicated bare-metal servers long before they hit the financial break-even point. Why? Because the cost-per-token is only half of the equation. Self-hosting provides massive operational advantages that cloud APIs legally and technically cannot offer.
-
1. Absolute Data Privacy and Compliance
If you are building AI for healthcare (HIPAA), finance (SOC2), or legal tech, sending highly sensitive client data to a third-party API is often a massive compliance violation. Even if the API provider promises not to train on your data, your enterprise clients will demand physical data isolation. Running open-source models on an iDatam dedicated server guarantees that your data never leaves the hardware you control. -
2. Zero Rate Limiting
APIs throttle you. If you launch a new feature and experience a sudden 10x spike in user traffic, your cloud API provider will hit you with HTTP 429 errors, breaking your app for users right when they want it most. With an iDatam unmetered dedicated server, there are no artificial tokens-per-minute limits. Your only limit is the raw compute physics of the GPU. -
3. Total Control Over Model Fine-Tuning
When you rely on a managed API, the provider can deprecate your favorite model at any time, forcing you to rewrite your prompts. When you self-host on iDatam, the model belongs to you. You can easily hot-swap base models with your own highly specialized, fine-tuned adapters (LoRA) to achieve GPT-4 level accuracy on specific tasks at a fraction of the parameter count. -
4. Predictable Burn Rates
Investors hate unpredictable infrastructure bills. A viral weekend shouldn't bankrupt your startup. Renting an iDatam dedicated GPU server transforms your AI inference cost from a terrifying, variable operational expense (OpEx) into a completely flat, predictable monthly line item.
The Bottom Line
The narrative that "self-hosting AI is too expensive" is a myth pushed by massive cloud providers. While APIs are fantastic for prototyping and low-volume apps, they act as a tax on your growth at scale.
If your AI application is scaling toward the 4 Billion token-per-month mark, or if you require absolute data privacy, migrating to an open-source model via vLLM on bare metal isn't just an option—it is a financial necessity.
iDatam Recommended Resources

Hardware
Why Are Intel, AMD, and Ampere Dominating the CPU Market?
When we choose a CPU, we had a lot to consider. However, the landscape of CPUs is mainly dominated by a few key companies depending on the market segment. No matter what kind of CPUs you're looking for, here's a breakdown of how things evolved and where they stand today.

Hardware
What is ARM?
ARM (Advanced RISC Machines) is a widely used family of RISC architectures developed by Arm Ltd., known for its energy efficiency and scalability. Since its founding in 1990, over 180 billion ARM-based chips have been shipped, making it the leading processor family globally.

Hardware
A Complete Guide to RAID Configurations: Balancing Performance and Data Protection
This guide digs into the world of RAID configurations, examining their advantages, disadvantages, and ideal use cases, as businesses and individuals increasingly seek ways to optimize their storage solutions in a data-driven world.
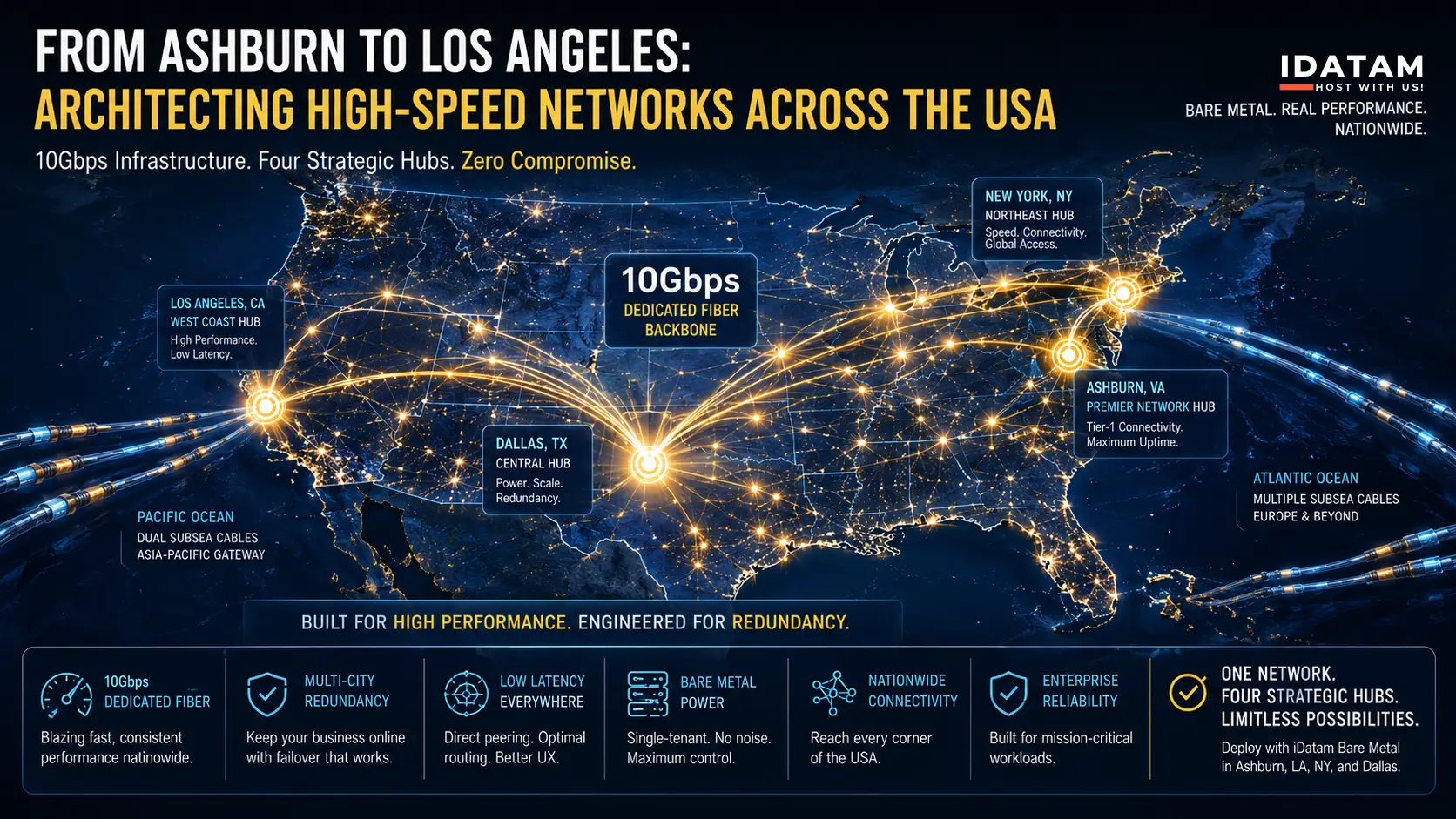
Discover iDatam Dedicated Server Locations
iDatam servers are available around the world, providing diverse options for hosting websites. Each region offers unique advantages, making it easier to choose a location that best suits your specific hosting needs.