The Hook: The Two Titans of 2026 Silicon
If you have glanced at the tech news cycle recently, you know that 2026 is shaping up to be a defining year for computational hardware. Two massive announcements are currently dominating the conversation: the release of the highly anticipated Apple M5 Max and the rollout of the NVIDIA Rubin architecture.
On one side, you have the tech media hyping up the Apple M5 Max, specifically its massive unified memory, as an unprecedented "local AI powerhouse." Influencers and early adopters are confidently proclaiming that developers can now seamlessly train an LLM locally while sipping a latte at a coffee shop. On the other side, you have NVIDIA pushing the boundaries of data-center scale computing with Rubin, setting new benchmarks for raw throughput and deep learning capabilities.
The core thesis here is simple, yet often ignored by gadget enthusiasts: consumer laptops are trying desperately to mimic data centers, but physics always wins. While the M5 Max is an engineering marvel, the harsh reality is that training, fine-tuning, and deploying enterprise-grade models requires the raw compute of NVIDIA's new Rubin architecture on a bare-metal server. If you are a startup founder or an ML engineer debating whether to rely on dedicated GPU servers or pivot entirely to local AI inference, it is time to look past the marketing and dive into the architecture.
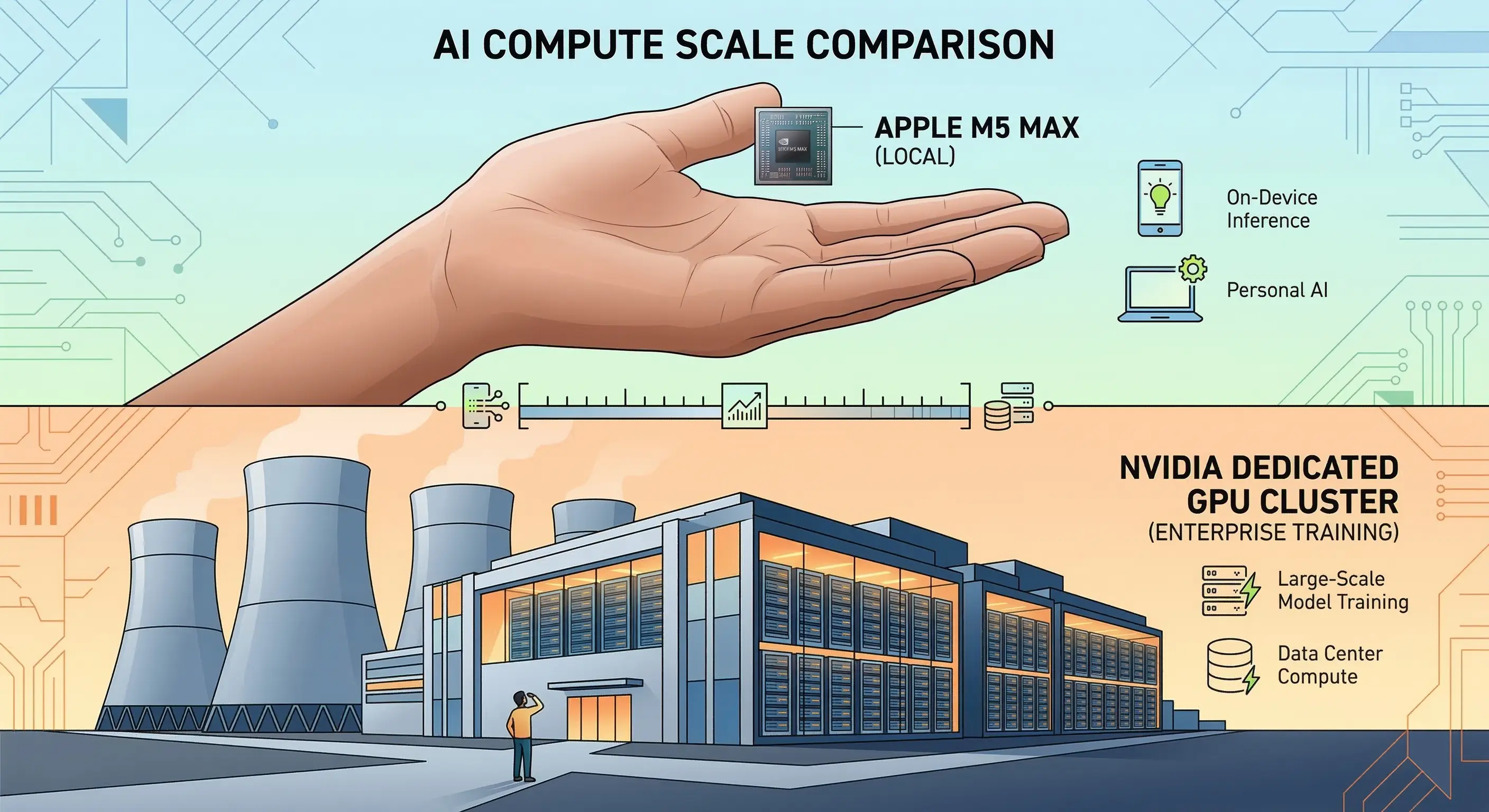
The Apple M5 Max: The Illusion of "Desktop AI"
Let's give credit where it is absolutely due: the Apple M5 Max is a phenomenal piece of consumer hardware. Apple has pushed its silicon to new heights, particularly with the inclusion of 128GB of high-bandwidth unified memory. For AI, memory is often the first bottleneck. The ability to load massive, multi-billion parameter models directly into RAM without relying on slow PCIe transfers between a CPU and a discrete GPU is a massive advantage. Paired with Apple's new "super cores," the M5 Max handles single-threaded tasks and localized matrix multiplication beautifully.

If you are a solo developer looking to run inference on a quantized Llama-3 model, the M5 Max feels like magic. You can prompt, test, and build retrieval-augmented generation (RAG) pipelines locally with zero latency and complete data privacy.
However, there is a hard pivot when you transition from simply using an AI model to training one. This is where the illusion of "desktop AI" shatters.
The M5 Max lacks the raw Floating Point Operations Per Second (FLOPS) necessary to train or heavily fine-tune models from scratch in a commercially viable timeframe. When you attempt to run sustained, high-intensity compute cycles, a laptop chassis—no matter how well-engineered—will inevitably run into thermal throttling. Furthermore, Apple relies on its Metal API. While Metal has improved, it simply cannot compete with the sheer dominance of the CUDA ecosystem. Trying to force enterprise-grade AI frameworks to play nicely with a laptop's proprietary graphics API often results in missing libraries, unoptimized execution, and hours wasted on debugging rather than building.
NVIDIA Rubin: The Architecture of True AI

When you move past tinkering and need to build a competitive AI product, you need heavy artillery. This is exactly what the NVIDIA Rubin architecture was engineered to be: a foundational leap forward for data centers and the definitive standard for true AI workloads.
Rubin does not just iterate on previous generations; it completely reimagines how data flows. At the heart of this architecture are the R100 GPUs paired with the highly anticipated Vera CPU, connected via next-generation NVLink. Crucially, Rubin utilizes HBM4 (High Bandwidth Memory), which shatters previous memory-wall limitations, allowing data to be fed into the compute cores faster than ever before.
One of the most significant breakthroughs with Rubin is its capacity for "disaggregated inference." In the past, massive models required everything to be perfectly localized. Rubin's architecture allows for massive context windows to be processed across a networked fabric of GPUs simultaneously. If you tried to feed a multi-million token context window into an Apple M5 chip, the system would instantly crash or freeze under the weight of the memory allocation. Rubin handles it without breaking a sweat.
Beyond the silicon, Rubin's greatest moat is software. The entire deep learning ecosystem—from PyTorch to TensorFlow, JAX to Hugging Face—is natively optimized for NVIDIA CUDA. When you deploy on Rubin, you are operating on the native language of artificial intelligence. Every operator, every library, and every community fix is designed for this architecture first. You aren't compiling workarounds; you are utilizing the absolute bleeding edge of machine learning technology.
The Economics: Capital Expense vs. Operational Agility
For an AI startup founder, hardware decisions are not just about specs; they are about runway, cash flow, and agility. The debate between buying high-end laptops versus utilizing cloud infrastructure comes down to Capital Expenditure (CapEx) versus Operational Expenditure (OpEx).
The CapEx Trap
It is tempting to look at your engineering team and think, "Let's just buy everyone a maxed-out M5." But let's run the math. Outfitting a team of eight engineers with top-tier Apple M5 Max laptops will easily run you upward of $40,000 in upfront capital.
What do you get for that investment? You get hardware that will aggressively depreciate over the next 18 months. You get machines that will melt under sustained, heavy training workloads, reducing their lifespan and frustrating your developers when builds take days instead of hours. You are effectively locking your startup's maximum compute ceiling to the thermal limits of a 16-inch aluminum chassis.
The OpEx Solution
The smarter, leaner path is operational agility. Renting an iDatam GPU Dedicated Server completely flips the economic model. Instead of sinking tens of thousands of dollars into depreciating assets, you convert your compute needs into a scalable monthly expense.
Renting bare-metal NVIDIA hardware provides your team with scalable access to data-center-grade silicon. You aren't just getting the GPUs; you are getting the entire infrastructure required to support them. This includes unmetered 100Gbps network speeds, which are absolutely critical when you are transferring multi-terabyte datasets. You get enterprise-grade cooling, redundant power, and zero hardware depreciation risk. If your model size doubles next month, you don't need to throw away your laptops and buy new ones; you simply scale your server footprint with a few clicks.
The Verdict: Keep the Mac for Coding, Rent the Server for Computing
We are not suggesting that the Apple M5 Max has no place in a machine learning workflow. In fact, the optimal workflow for a modern 2026 developer leverages the strengths of both paradigms.
The ideal setup is hybrid. Keep the M5 Max for what it does best: acting as an incredible, portable client. Use it to write your code, test small scripts, run inference on quantized models, and manage your data pipelines. It is the ultimate interface for a developer.
But when it is time to do the real work—when you need to push heavy training jobs, fine-tune a foundation model on your proprietary data, or serve a production API to thousands of concurrent users—push that workload to a dedicated NVIDIA server. Let the M5 handle the logic, and let Rubin handle the heavy lifting. Physics always wins, and when it comes to raw computational throughput, a data center will outclass a laptop every single time.
Elevate Your AI with iDatam
Don't bottleneck your startup's AI potential on laptop hardware. While consumer silicon is great for drafting concepts, enterprise models require enterprise compute. Deploy your models on iDatam's bare-metal NVIDIA clusters today and get data-center performance for a flat monthly rate. Experience the power of the latest NVIDIA architecture, zero bandwidth throttling, and the scalability your startup needs to outpace the competition.
Ready to scale? Explore our GPU Dedicated Servers today.
iDatam Recommended Resources

Hardware
Why Are Intel, AMD, and Ampere Dominating the CPU Market?
When we choose a CPU, we had a lot to consider. However, the landscape of CPUs is mainly dominated by a few key companies depending on the market segment. No matter what kind of CPUs you're looking for, here's a breakdown of how things evolved and where they stand today.

Hardware
What is ARM?
ARM (Advanced RISC Machines) is a widely used family of RISC architectures developed by Arm Ltd., known for its energy efficiency and scalability. Since its founding in 1990, over 180 billion ARM-based chips have been shipped, making it the leading processor family globally.

Hardware
A Complete Guide to RAID Configurations: Balancing Performance and Data Protection
This guide digs into the world of RAID configurations, examining their advantages, disadvantages, and ideal use cases, as businesses and individuals increasingly seek ways to optimize their storage solutions in a data-driven world.
Discover iDatam Dedicated Server Locations
iDatam servers are available around the world, providing diverse options for hosting websites. Each region offers unique advantages, making it easier to choose a location that best suits your specific hosting needs.